Announcing the Upworthy Research Archive
By J. Nathan Matias, Assistant Professor, Department of Communication, Cornell University
The original version of this article appeared on Medium. This content is licensed under CC By-SA 4.0
Help us advance human understanding by studying this massive dataset of headline A/B tests
Remember these headlines?

2014 was the year that the digital media company Upworthy “broke the internet” in the words of cofounder Peter Koechley. By publishing positive, progressive news stories and optimizing them with A/B testing, Upworthy came to dominate online attention.
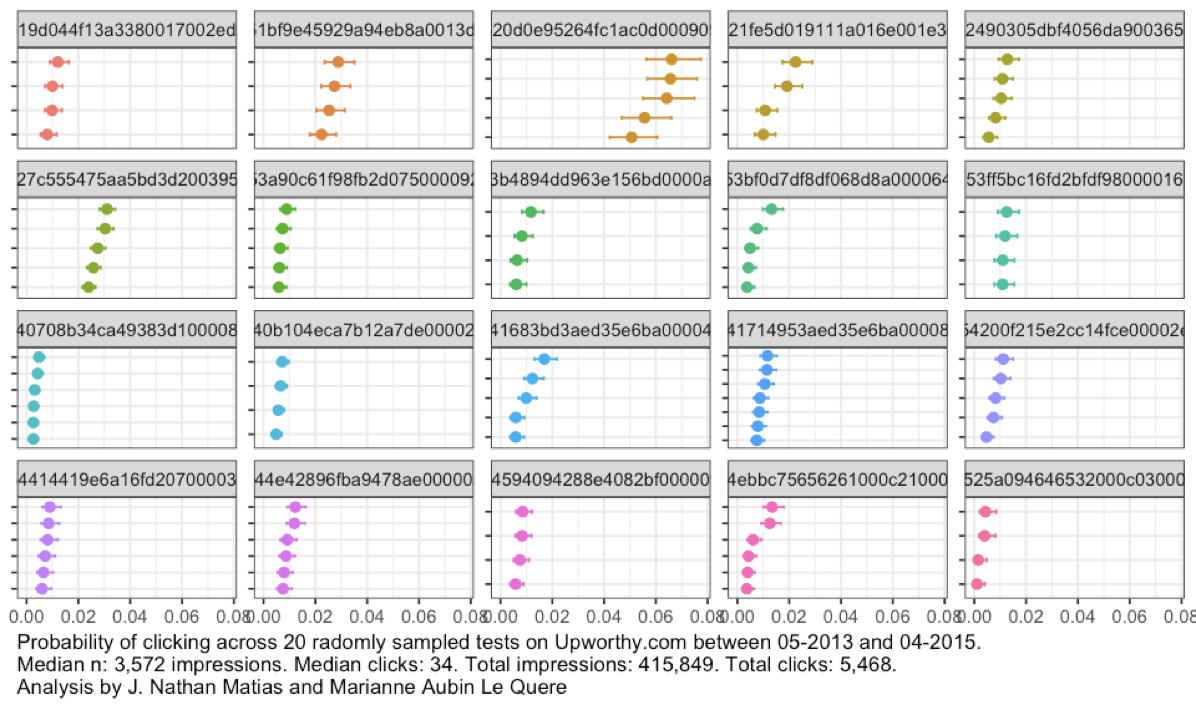
What can we learn from all those A/B tests? Today, Good & Upworthy and our team of J. Nathan Matias (Cornell), Kevin Munger (Penn State), and Marianne Aubin Le Quere (Cornell) are announcing The Upworthy Research Archive, a dataset of 32,487 A/B tests conducted by Upworthy from January 2013 to April 2015. When released, we believe it will be the largest collection of randomized behavioral studies available for research and educational purposes.
We believe Upworthy’s A/B tests can help us advance knowledge in many fields, including communication, political science, psychology, statistics, and computer science
If you would like to do research with this dataset, we want to hear from you! Please complete this short form by November 30, 2019!

Upworthy’s traffic peaked in November 2013 when the company reached more people than the New York Times. In response, Facebook created one of its first widely-publicized algorithmic policies in 2014. Facebook’s algorithm attempts to re-balance the NewsFeed significantly affected Upworthy and set the stage for the company’s later algorithmic policies. Ever since, the quest for virality has been an adversarial competition between publishers and platforms. In 2017, Upworthy merged with Good Worldwide.
What the archive includes
Upworthy conducted its A/B tests on its own website, randomly varying different “packages” for a single story– a headline, subhead, social media summary, and thumbnail.
While we’re still verifying the data, we can confirm that each A/B test in the archive will include:
Headline variations
Subhead variations
Social media summary, where Upworthy used them
The number of impressions
The number of clicks
In some cases, the “winner” chosen by the company
The whole dataset includes 32,487 valid deployed tests, including 150,817 total tested packages. We also have access to Upworthy’s Google Analytics data for this time period, allowing us to record average estimated demographic information about website viewers over time. We’re still investigating the best way to do this.
Why this archive matters
We live in a society where companies and political campaigns test and influence the behavior of millions of people every day. Used wisely, these capabilities could advance human understanding and guide decisions for flourishing democracies. We also need to better understand this power to protect society from its misuses. Upworthy’s A/B tests can help us advance knowledge in many fields, including:
Political Science, Psychology, and Communication theories on the language that influences people to click on articles
Organizational Behavior research on how firms learn over time (or not) through experimentation
Statistical advances in the analysis of experiments
Deeper questions about the knowledge from behavioral experiments and how useful they are at predicting future outcomes
Computer Science research on machine learning and cybersecurity
This dataset will also support classes like Nathan’s class on The Design and Governance of Field Experiments, where students learn how to do experiments and think about ways to govern this kind of behavioral power.
The Upworthy Research Archive will also help level the playing field for research and teaching about online behavior. Right now, only a few academic researchers can negotiate access to data from the thousands of A/B tests that companies conduct every year. Students never have a chance to get hands-on experience with this kind of knowledge. Our dataset will change that.

Calling All Researchers: How To Work With the Upworthy Research Archive
Through an agreement been Good and Cornell University, we have been granted complete permission to publish the dataset openly. We’re still reviewing and cleaning the dataset, which will only include aggregate results and will not include any identifiable information about individuals. We also expect to have general demographic information about the kind of people who were viewing Upworthy during a given study.
We plan to release the data in stages to increase the credibility of the initial scientific discoveries. Given a large enough dataset, it’s easy to fish for answers, even with good intentions. Inspired by lessons from the Fragile Families Challenge and the Psychological Science Accelerator, we are planning a multi-stage process for:
open, exploratory analysis on a small number of studies
registered reports that are peer-reviewed
cross-validating the pre-registered analyses on the full dataset
publishing the results
(after a time) publishing the full dataset
To set up that process we need academics and educators to tell us what you would do with this data. Once we know what people from different fields want to do with the dataset, we will be able to design a process to ensure the broadest high-quality contribution to knowledge from the Upworthy Archive.
For more details, you can see our announcement slides and the short paper we shared at the MIT Conference on Digital Experimentation in November 2019.
If you would like to work with this dataset, please complete this short form by November 30, 2019. If you have questions, consider reaching out to Nathan, Kevin, and Marianne on Twitter at @natematias, @kmmunger, and @marianneaubin to keep the conversation broad and open. We will also accept emails at nathan.matias@cornell.edu and <kmm7999@psu.edu>.









