Manage evolving coding schemes in a codebook: Three simple strategies
by Dr. Jenine Beekhuyzen, CEO of Adroit Research and the Founder of the Tech Girls Movement. This post was originally published on the NVivo Blog.
I originally began writing this blog post about teamwork and my recent experiences in seeing how important it is to clarify the definitions of codes when working in teams.
But I now realize that such advice applies to all researchers, in all disciplines, studying all manner of topics. Every single researcher I have discussed this with (and they are now in the hundreds) has found some benefit in this, so I had to share it with you. (Thanks QSR for inviting me to write this post!)
The topic of a codebook came to my immediate attention when I read the article “Developing and Using a Codebook for the Analysis of Interview Data: An Example from a Professional Development Research Project” by DeCuir-Gunby, Marshall and McCulloch, which was published in the Field Methods journal in 2010. This article has become my research bible.
I have seen how it helps to fix some of the challenges that researches face when coding qualitative data. How?
What's in a name?
We all approach our data with the best of intentions, equipping ourselves with the tools (e.g. NVivo) and techniques (e.g. thematic analysis) we believe we need to do an adequate, and hopefully even good analysis of the data we often struggled many months or years to collect.
We often feel we have clear conceptualizations of what we mean by different codes related to our data. But often we don’t document these in detail. It just seems too hard doesn’t it?
Believe me, the tedious work is well worth it!
I find that most of us are not very articulate about what we mean by each of the codes we are using to investigate the data. How do you decide what is included in a node and what is not? How would you describe your process to someone else (i.e. your examiners!) and create a process that is repeatable?
The codebook is the answer.
It helps to clarify codes and what you mean when you apply them to your data not only to yourself, but also to your team members and supervisory staff.
I’ve seen experienced teams convinced that they are all on the same page about their codes, but when given the task of developing a codebook in a systematic way, they find they often have different understandings of what they mean by common terms.
So my regular first response in consulting and training now related to qualitative data analysis is – where is your codebook?
Strategy 1. Create the codebook
You can export your nodes and their descriptions to create a codebook from your NVivo data.
To take this further you could open the codebook in Word and add an 'Example from text' column to demonstrate how each code is used:
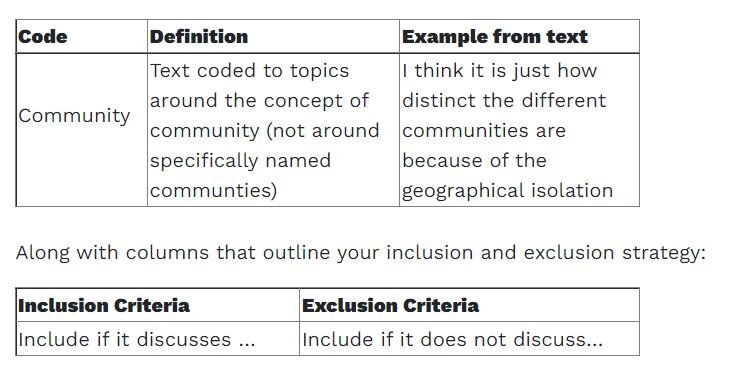
Tables with example of Code, definition, example, and inclusion or exclusion criteria
Then import the document back into your NVivo project so that you can refer to it regularly.
The benefits become obvious pretty quickly; you know exactly what you mean by each code, as does your supervisor/s and ultimately your examiner/s. This is really important, in my opinion, to all research projects postgrad and postdoc.
The benefits for teams are also immediately apparent: each person coding knows exactly what should be coded in each node and what should be added to another or a new code – much of the ambiguity disappears as does much of the angst of the coder.
Strategy 2. Document the changes to your codebook
If you are using apriori (theoretically or domain based) codes then you might find this coding process fairly straightforward.
However if you are doing thematic analysis with codes that are not well defined from the start, then your codebook WILL change. Be prepared for that. It might get messy before it gets clear, that’s ok :)
A recent psychology study found it took quite a few interviews before the team codebook was agreed upon in these instances, and my own experience is seeing teams nut it out for hours on end sometimes to get finally definitions and examples that everyone agrees upon.
This is good progress and a really important stage in the data analysis/coding process!
Strategy 3. Run an intercoder reliability check (specifically for teams)

A Coding Comparison query
After the team creates a codebook of their codes, each coder then takes a copy of the NVivo project (appended with their initials) and goes away and codes the same interview to a set of identified codes that are believed to be well defined from strategy #1.
Once the coding is complete, use NVivo to run a query to compare the coding from each coder. This is a great process to help to create really strong definitions of your codes (and test them out), as it becomes really obvious from the result of the query where the ideas and conceptualisations of the coders differ. NVivo allows you to look at exactly where the differences are, and these are then discussed with the team.
Once some decisions are made, often these include whether to code the question in addition to the response, or whether to code a line or a paragraph, then the team goes away and repeats this process with a second data source (often another interview transcript).
Run the query again and discuss the results with the aim of being as closely compatible in coding as possible (NVivo also provides a Kappa as a representation of this compatibility). The Kappa and a description of your process of coding can be used to report your teamwork.























