
Qualitative Research Design and Data Analysis: Deductive and Inductive Approaches
How to use different forms of reasoning to interpret data.

Qualitative Data Analysis: Thick Meaning and Case Studies
Excellent data analysis resources for qualitative researchers from Margaret Roller.

Devising Research Methods, and Analysis
Devising new methods? Dr. Helen Kara discusses strategies for creative researchers.

Analyze Big Data
Want to learn about Big Data analysis? Here are some open-access examples.


Interpreting Data and Making Claims: Interview with Charles Vanover, Paul Mihas, and Johnny Saldana
Welcome a new month's focus on data analysis, with Mentors in Residence Charles Vanover, Paul Mihas, and Johnny Saldana.

Photovoice and Visual Data: Articles
Want to learn more about photovoice? Here are some open-access articles!


Practical Tips for Getting Started with Harvesting and Analyzing Online Text
How can you collect and analyze text you find online?

Online Research: Analyze Talk
See two informative video interviews with Trena Paulus and co-authors Jessica Lester and Alyssa Wise.


Emotion and reason in political language
In the day-to-day of political communication, politicians constantly decide how to amplify or constrain emotional expression, in service of signalling policy priorities or persuading colleagues and voters. We propose a new method for quantifying emotionality in politics using the transcribed text of politicians’ speeches. This new approach, described in more detail below, uses computational linguistics tools and can be validated against human judgments of emotionality.
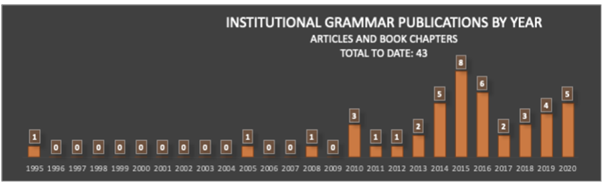
Understanding institutions in text
Institutions — rules that govern behavior — are among the most important social artifacts of society. So it should come as a great shock that we still understand them so poorly. How are institutions designed? What makes institutions work? Is there a way to systematically compare the language of different institutions? One recent advance is bringing us closer to making these questions quantitatively approachable. The Institutional Grammar (IG) 2.0 is an analytical approach, drawn directly from classic work by Nobel Laureate Elinor Ostrom, that is providing the foundation for computational representations of institutions. IG 2.0 is a formalism for translating between human-language outputs — policies, rules, laws, decisions, and the like. It defines abstract structures precisely enough to be manipulable by computer. Recent work, supported by the National Science Foundation (RCN: Coordinating and Advancing Analytical Approaches for Policy Design & GCR: Collaborative Research: Jumpstarting Successful Open-Source Software Projects With Evidence-Based Rules and Structures ), leveraging recent advances in natural language processing highlighted on this blog, is vastly accelerating the rate and quality of computational translations of written rules.

text: An R-package for Analyzing Human Language
In the field of artificial intelligence (AI), Transformers have revolutionized language analysis. Never before has a new technology universally improved the benchmarks of nearly all language processing tasks: e.g., general language understanding, question - answering, and Web search. The transformer method itself, which probabilistically models words in their context (i.e. “language modeling”), was introduced in 2017 and the first large-scale pre-trained general purpose transformer, BERT, was released open source from Google in 2018. Since then, BERT has been followed by a wave of new transformer models including GPT, RoBERTa, DistilBERT, XLNet, Transformer-XL, CamemBERT, XLM-RoBERTa, etc. The text package makes all of these language models and many more easily accessible to use for R-users; and includes functions optimized for human-level analyses tailored to social scientists.

How can you analyze online talk? Researchers demonstrate!
This interview was a show-and-tell about analyzing online talk.
Christina Silver and the Five-Level QDA Method
Find an introduction to the Five-Level QDA Method and related resources.

The validity problem with automated content analysis
There’s a validity problem with automated content analysis. In this post, Dr. Chung-hong Chan introduces a new tool that provides a set of simple and standardized tests for frequently used text analytic tools and gives examples of validity tests you can apply to your research right away.
My journey into text mining
My journey into text mining started when the institute of Digital Humanities (DH) at the University of Leipzig invited students from other disciplines to take part in their introductory course. I was enrolled in a sociology degree at the time, and this component of data science was not part of the classic curriculum; however, I could explore other departments through course electives and the DH course sounded like the perfect fit.
How to embrace text analysis as a computational social scientist
In this guest blog, Alix Dumoulin and Regina Catipon cover how to embrace text analysis as a social scientist, the challenge cleaning text corpora brings in preprocessing, and introduce our upcoming tool, Texti, that will save researchers time.
From preprocessing to text analysis: 80 tools for mining unstructured data
Text mining techniques have become critical for social scientists working with large scale social data, be it Twitter collections to track polarization, party documents to understand opinions and ideology, or news corpora to study the spread of misinformation. In the infographic shown in this blog, we identify more than 80 different apps, software packages, and libraries for R, Python and MATLAB that are used by social science researchers at different stages in their text analysis project. We focused almost entirely on statistical, quantitative and computational analysis of text, although some of these tools could be used to explore texts for qualitative purposes.