Recent Advances in Partial Least Squares Structural Equation Modeling: Disclosing Necessary Conditions
by Joseph F. Hair, Jr. ,Marko Sarstedt, Christian M. Ringle and Siegfried P. Gudergan
See a previous post: Partial Least Squares Structural Equation Modeling: An Emerging Tool in Research.
Two Sage books are being recognized and cited at a rapidly increasing rate, and in combination recently exceeded 50,000 citations in a few short years. They also have been translated into eight languages (Arabic, French, German, Italian, Korean, Persian, Spanish, and Vietnamese) and will soon be available in Malay (forthcoming later this year). This success is the result of the rapid expansion in analytical extensions of the method of partial least squares structural equation modeling (PLS-SEM).
Necessary condition analysis (NCA)
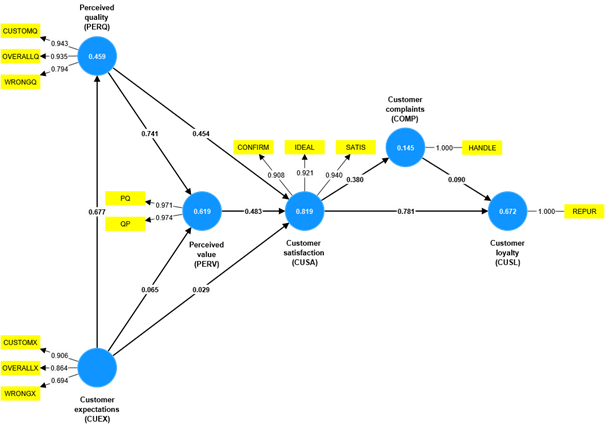
Among the most recent options available in the dynamic landscape of emerging methodological extensions in the PLS-SEM field is the necessary condition analysis (NCA). In short, the merger of these two analytical methods provides researchers a comprehensive toolkit to explore the complex interrelationships between constructs and, at the same time, identify necessary conditions for specific outcomes. The NCA enables the identification of ‘must-have’ factors – those conditions which need to be met to achieve a certain outcome level. This necessity logic extends PLS-SEM’s sufficiency logic according to which each antecedent construct in a structural model is sufficient (but not necessary) for producing changes in the dependent construct. The figure below shows a PLS path model with its estimated relationships obtained by using the SmartPLS 4 software. For example, the results show the relationship from perceived quality (PERQ) to customer satisfaction (CUSA) is relatively strong. Based on PLS-SEM’s sufficiency logic, an increase in PERQ corresponds to a higher level of variance explained in the dependent construct CUSA.

Digging deeper, however, intuition tells us the “the more the better” perspective is just one side of the coin. For example, it is reasonable to assume a certain level of PERQ must be achieved to trigger CUSA in the first place. Similarly, achieving a high level of CUSA may not require maximizing PERQ. Analyzing this relationship with the NCA (e.g., via the SmartPLS 4 software,) produces a ceiling line (the grey line in the following figure labeled CR-FDH), which indicates the outcome level (y-axis) that can be achieved for a certain input (x-axis). For example, looking at the chart, we find that a CUSA level of 7 or higher can only be achieved for a PERQ value of at least 3.

Recent research provides guidelines for executing an NCA in a PLS-SEM, explaining relevant outputs such as the bottleneck table and the necessity effect size. Researchers have also suggested further extensions of the PLS-SEM-based NCA by combining its results with those from an importance-performance map analysis (IPMA), which adds a further dimension to the analysis. Specifically, the combined IPMA (cIPMA) ties together the structural model effects, the rescaled constructs’ scores, indicating their performance, and the NCA results. Related to our example above, researchers can use the cIPMA to identify satisfaction drivers, which have a strong effect on CUSA, are necessary, and whose performance is relatively low.
Learn more about partial least squares structural equation modeling


To get to know the PLS-SEM method, the third edition of A Primer on Partial Least Squares Structural Equation Modeling (PLS-SEM) by Joe Hair, Thomas Hult, Christian Ringle, and Marko Sarstedt, and the second edition of Advanced Issues in Partial Least Squares Structural Equation Modeling by Hair, Sarstedt, Ringle, and Siegfried Gudergan, are practical guides that provide researchers with a shortcut to fully understand and competently use the rapidly emerging multivariate PLS-SEM technique.
While the primer offers an introduction to fundamental topics such as establishing, estimating and evaluating PLS path models and some additional topics such as mediation and moderation, the book on advanced issues fully focuses on complementary analyses such as testing nonlinear relationships, latent class segmentation, multigroup analyses, measurement invariance assessment, and higher-order models. Featuring the latest research, examples analyzed with the SmartPLS 4 software, and expanded discussions throughout, these two books are designed to be easily understood by those want to exploit the analytical opportunities of PLS-SEM in research and practice. There is also an associated website for both books. Use the code COMMUNIT24 for a 25% discount when you order books from Sage, good until December 31, 2024.
Literature about the PLS-SEM method
Dul, J. (2016). Necessary Condition Analysis (NCA): Logic and Methodology of "Necessary but not Sufficient" Causality. Organizational Research Methods, 19(1), 10-52.
Dul, J. (2020). Conducting Necessary Condition Analysis. Sage.
Hair, J. F., Hult, G. T. M., Ringle, C. M., & Sarstedt, M. (2022). A Primer on Partial Least Squares Structural Equation Modeling (PLS-SEM) (3 ed.). Sage.
Hair, J. F., Sarstedt, M., Ringle, C. M., & Gudergan, S. P. (2024). Advanced Issues in Partial Least Squares Structural Equation Modeling (PLS-SEM) (2 ed.). Sage.
Hauff, S., Richter, N. F., Sarstedt, M., & Ringle, C. M. (2024). Importance and Performance in PLS-SEM and NCA: Introducing the Combined Importance-Performance Map Analysis (cIPMA). Journal of Retailing and Consumer Services, 78, 103723.
Richter, N. F., Hauff, S., Kolev, A. E., & Schubring, S. (2023). Dataset on an Extended Technology Acceptance Model: A Combined Application of PLS-SEM and NCA. Data in Brief, 48, 109190.
Richter, N. F., Schubring, S., Hauff, S., Ringle, C. M., & Sarstedt, M. (2020). When Predictors of Outcomes are Necessary: Guidelines for the Combined use of PLS-SEM and NCA. Industrial Management & Data Systems, 120(12), 2243-2267.
Sage Research Methods Community posts about quantitative data analysis






















Find tips to help you share your research and numerical findings.